概述
交叉熵误差是机器学习中,尤其是分类问题中广泛使用的损失函数。它用于衡量模型预测的概率分布与实际标签的真实分布之间的差异。
定义
对于二分类问题,设模型输出的预测概率为 ,即给定输入 ,样本属于类别1的概率;而真实标签为 (0或1)。则交叉熵损失函数定义为:
对于多分类问题,假设我们有 个类别,则模型输出的是一个 维的概率向量 ,其中每个元素表示属于对应类别的概率。若 是真实的类别标签(通常是一个one-hot向量),则交叉熵损失函数定义为:
这里, 表示第 类的实际概率(0或1), 表示模型预测的第 类的概率。
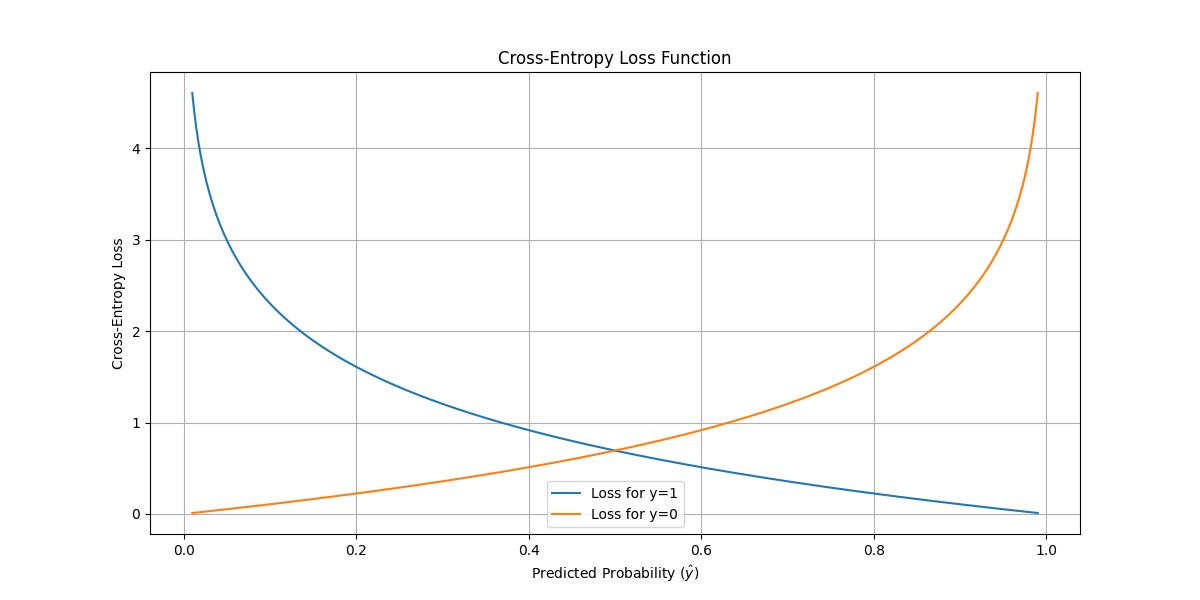
- 当 时(即实际类别是正类):
- 当 (模型完全确信这个样本属于正类),损失 。
- 随着 的值减小(模型变得不那么确信),损失迅速增加。
- 当 接近于0时(模型非常确信这个样本不属于正类,这与实际情况相反),损失接近无穷大。
- 当 时(即实际类别是负类):
- 当 (模型完全确信这个样本不属于正类),损失 。
- 随着 的值增加(模型变得不那么确信或错误地偏向正类),损失迅速增加。
- 当 接近于1时(模型非常确信这个样本属于正类,这与实际情况相反),损失接近无穷大。
梯度计算
假设由softmax生成,, 是模型输出的原始分数。
计算损失 对原始分数 的梯度
计算
计算Softmax的导数
- 当 时:
- 当 时:
综上可得:
其中 是Kronecker delta函数( 当且仅当 ,否则为0)。
带回到原式
展开求和项:
- ** 的贡献**:
- ** 的贡献**:
合并结果:
关键性质:由于真实标签 是概率分布(),最终化简为:
优点和缺点
优点
- 适用于概率估计
- 交叉熵直接度量了两个概率分布间的差异,非常适合于分类任务。
- 解决非线性问题能力强
- 通过优化交叉熵损失,可以有效地训练复杂的非线性模型,如神经网络。
- 对正确分类的置信度敏感
- 如果模型对正确类别的预测非常自信(接近1),则损失会很低;反之,如果预测错误或者不自信(远离0或1),损失会很高。
缺点
- 对数据质量要求高
- 交叉熵损失函数对数据集中的噪声和错误标签较为敏感。在存在大量噪声的情况下,可能会导致模型性能下降。
- 可能产生过拟合
- 特别是在数据集较小的情况下,过于追求低交叉熵损失可能导致模型过拟合训练数据,从而影响其泛化能力。